
MySQL多个Sending Data状态的进程导致SQL执行查询耗时长
场景
数据量十几万的数据表,一个简单的 join 联表查询平均耗时 30s 以上。
1 | SELECT |
event_signal_actual 表数据量十几万,subsystem_info 数据量十几条数据。
SQL 在测试服执行耗时是毫秒级别的,只是在正式服耗时 30s 以上。
排查思路
大概思路就是:EXPLAIN 分析 -> SHOW PROFILE 分析 -> MySQL 实例分析 -> SHOW PROCESSLIST 分析。
- EXPLAIN 分析 SQL 语句,从 SQL 自身和索引方面优化。
- SHOW PROFILE 分析 SQL 执行中的各个阶段。
- 从 MySQL 实例找原因,例如全局参数 innodb_buffer_pool_size 是否合理等等。
- SHOW PROCESSLIST 打印 MySQL 实例上当前正在执行的查询、连接状态和相关信息,从而进行性能监控、问题排查和优化。例如是否有大量查询卡在 Sending data 阶段。
EXPLAIN查询执行计划
在 MySQL 中,EXPLAIN 是一个用于查看查询执行计划的命令。可以帮助分析查询是如何在数据库内部执行的,以及如何使用索引来提高性能。
EXPLAIN 分析 SQL 语句,结果如下表所示,Extra 中的 Using filesort 表示查询需要进行文件排序操作。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | esa | range | IDX_SOURCE | IDX_SOURCE | 99 | 22948 | 9.00 | Using index condition; Using where; Using filesort | ||
| 1 | SIMPLE | si | ref | IDX_SYSTEM_CODE | IDX_SYSTEM_CODE | 99 | pcs9700.esa.SOURCE | 1 | 100.00 | null |
新增 HAPPEN_TIME 字段的索引 idx_happen_time 优化 SQL ,再次 EXPLAIN 分析,结果如下表所示。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | esa | index | IDX_SOURCE | idx_happen_time | 8 | 586 | 1.53 | Using where |
Using filesort 的问题已经优化,但是 SQL 在正式服执行仍然耗时 30s 以上。
接下来,执行一个简单、高效的 SQL 测试。
1 | SELECT |
EXPLAIN 分析如下:
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | esa | index | IDX_SOURCE | idx_happen_time | 8 | 100 | 100.00 | Using index |
可以看到,Extra 优化信息显示 Using index ,表示查询使用覆盖索引,不需要回表查询,这是一个查询性能高的语句。
但是即使是最大程度优化的 SQL ,在正式服执行仍然耗时 30s 以上。
SHOW PROFILE分析
SHOW PROFILE 是一个用于查看查询执行过程中详细信息的命令。它可以显示查询中各个阶段的耗时、资源使用情况等。SHOW PROFILE 命令需要在查询执行之后使用,它会返回一个包含多个不同阶段的性能数据集。
先执行要分析的 SQL 语句。
执行 SHOW PROFILES 查看会话中最近执行的查询和语句的性能分析数据,找到刚刚执行的 SQL 语句。
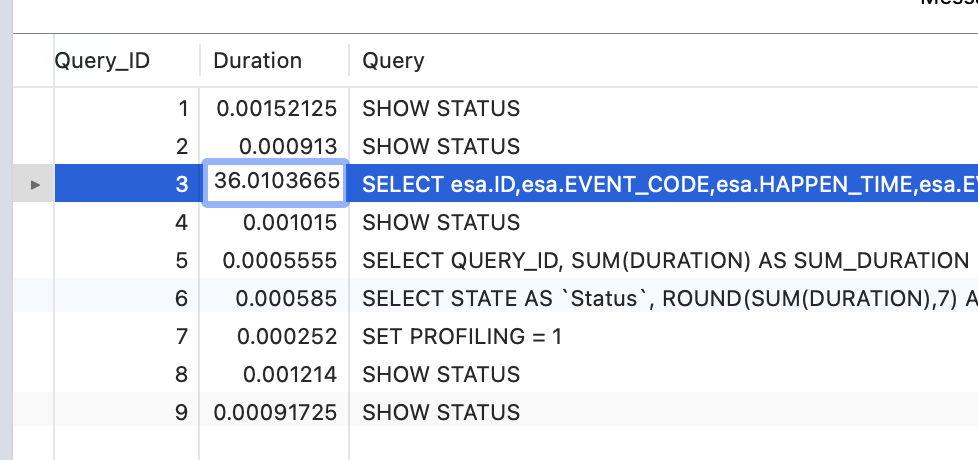
执行 SHOW PROFILE FOR QUERY 3 (3 为要分析的刚刚执行额 SQL 的 Query_ID)。
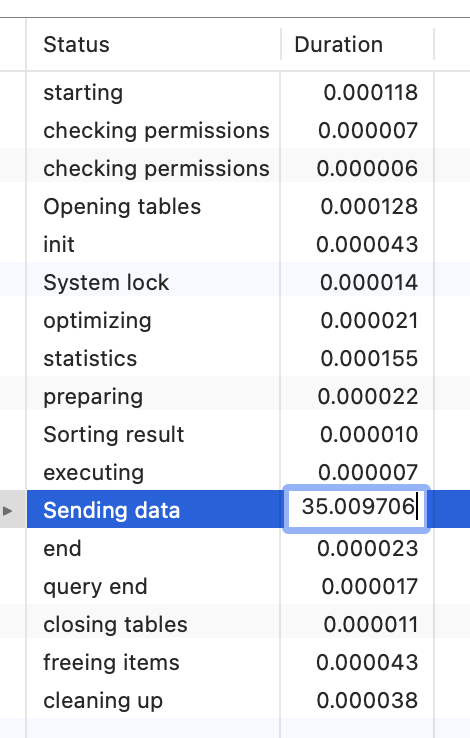
可以看到,SQL 执行过程中最耗时的就是 Sending data 阶段,官方解释如下:
官方文档:https://dev.mysql.com/doc/refman/5.7/en/general-thread-states.html
Sending dataThe thread is reading and processing rows for a
SELECTstatement, and sending data to the client. Because operations occurring during this state tend to perform large amounts of disk access (reads), it is often the longest-running state over the lifetime of a given query.该线程正在读取和处理 SELECT 语句的行,并将数据发送到客户端。由于在此状态期间发生的操作往往会执行大量磁盘访问(读取),因此它通常是给定查询生命周期中运行时间最长的状态。
接下来,调整 MySQL 实例参数配置,增大数据库缓存,减少磁盘 IO 次数。
Buffer Pool
Buffer Pool 是一个内存区域,用于缓存数据库表的数据和索引,以减少对磁盘的频繁读取操作。
Sending data 状态期间发生的操作往往会执行大量磁盘访问。查看 MySQL 的 buffer pool 配置,通过优化 buffer pool 配置,将磁盘数据页加载到缓存中,减少磁盘 IO 次数。
1 | mysql> SHOW GLOBAL VARIABLES LIKE 'innodb_buffer%'; |
可以看到 MySQL 实例的 innodb_buffer_pool_size 值为 128M 。
官方建议如下:
官方文档:https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_buffer_pool_size
A larger buffer pool requires less disk I/O to access the same table data more than once. On a dedicated database server, you might set the buffer pool size to 80% of the machine’s physical memory size. Be aware of the following potential issues when configuring buffer pool size, and be prepared to scale back the size of the buffer pool if necessary.
更大的缓冲池需要更少的磁盘 I/O 来多次访问相同的表数据。在专用数据库服务器上,您可以将缓冲池大小设置为计算机物理内存大小的 80%。
正式服 MySQL 单独部署在一个 64G 内存的服务器上,而 innodb_buffer_pool_size 却只设置了默认的 128M ,增大 innodb_buffer_pool_size 大小。
1 | SET GLOBAL innodb_buffer_pool_size = 40 * 1024 * 1024 * 1024 |
但无论设置 innodb_buffer_pool_size 为 20G、30G、40G,SQL 执行还是耗时 30s 以上。
SHOW PROCESSLIST
SHOW PROCESSLIST 是 MySQL 提供的一个用于查看当前活动连接和查询的命令。它可以帮助了解数据库服务器上当前正在执行的查询、连接状态和相关信息,从而进行性能监控、问题排查和优化。
SHOW PROCESSLIST 发现多个进程状态为 Sending data 。
查询 Sending data 状态的进程:
1 | SELECT * FROM information_schema.PROCESSLIST WHERE STATE='Sending data' ORDER BY TIME desc; |
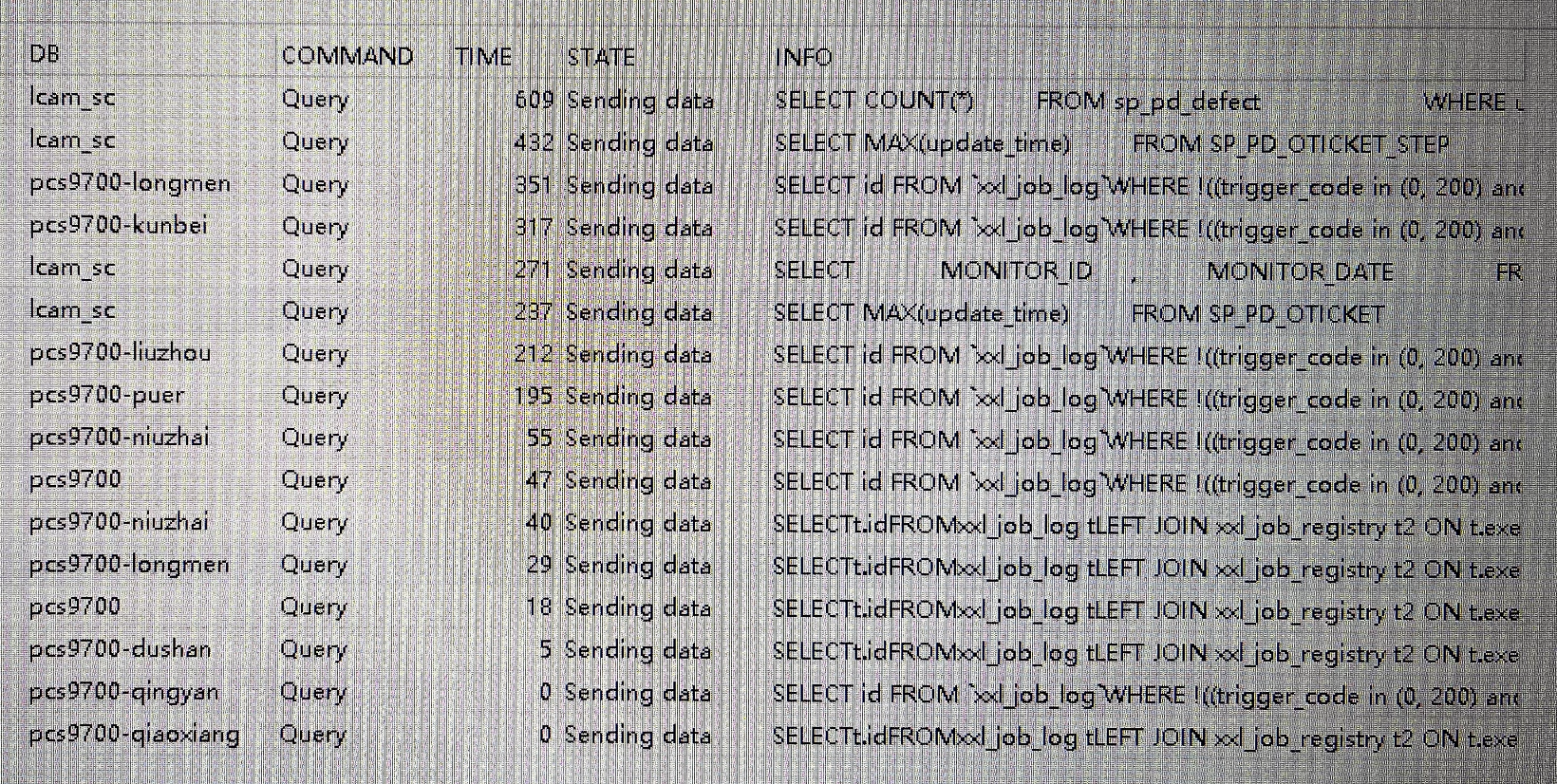
可以看到多个查询 xxl_job_log 表的进程在 Sending data 状态,查看每个库的 xxl_job_log 表发现数据量级超过了一千万,最大的有超过 1600w 的数据,占用 16G 磁盘空间,并且这是一个 order by 排序查询语句。
猜测是大量 xxl_job_log 的数据需要加载到内存中排序,占用大量 buffer_pool 内存空间,导致整个 MySQL 实例执行 SQL 查询效率慢,这也解释了无论设置 innodb_buffer_pool_size 为 20G、30G、40G,执行 SQL 查询都是那么慢。
接下来是清理 xxl_job_log ,这是一个 xxljob 调度日志数据表,配置 3 天的日志保留时间不生效导致数据积累到千万量级,直接 truncate 整个数据表(效率比 delete 快)。
delete 在 where 子句中指定时间范围删除千万量级的数据表耗时非常长,会生成事务日志,需要耐心等待。在 delete 执行期间不耐烦直接 kill 掉进程的话,会导致需要耗费更多时间去回滚数据(进程一只处于 killed 状态,直到回滚完成)。
truncate 执行期间会加 system lock ,可能会阻塞数据库所有操作。
清理完 xxl_job_log 后,执行 SHOW PROCESSLIST 可以看到所有在 Sending data 状态的进程都消失了。
最后,执行 SQL 也恢复正常的查询效率。
EXPLAIN参数详解
id:
SQL 执行的顺序表示,id 从大到小执行。id 相同时,执行顺序由上至下
select_type: 描述了查询的类型。常见的值包括:
类型 说明 SIMPLE 简单查询,不包含子查询或 UNION。 PRIMARY 主查询,包含 union 或者子查询(相关子查询),最外层的部分标记为 primary 。 SUBQUERY 子查询,通常出现在 SELECT列表或WHERE子句中。DERIVED 派生表,临时表,例如在 FROM子句中的子查询。UNION 联合查询,位于 union 中第二个及其以后的子查询被标记为 union,第一个就被标记为 primary ,如果是union 位于 from 中则标记为 derived 。 官方文档解释如下:
select_typeValueJSON Name Meaning SIMPLENone Simple SELECT(not usingUNIONor subqueries)PRIMARYNone Outermost SELECTUNIONNone Second or later SELECTstatement in aUNIONDEPENDENT UNIONdependent(true)Second or later SELECTstatement in aUNION, dependent on outer queryUNION RESULTunion_resultResult of a UNION.SUBQUERYNone First SELECTin subqueryDEPENDENT SUBQUERYdependent(true)First SELECTin subquery, dependent on outer queryDERIVEDNone Derived table DEPENDENT DERIVEDdependent(true)Derived table dependent on another table MATERIALIZEDmaterialized_from_subqueryMaterialized subquery UNCACHEABLE SUBQUERYcacheable(false)A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query UNCACHEABLE UNIONcacheable(false)The second or later select in a UNIONthat belongs to an uncacheable subquery (seeUNCACHEABLE SUBQUERY)table: 指示查询操作的表。
partitions: 如果查询涉及到分区表,这个字段会显示被访问的分区。
type: 描述了 MySQL 在表中找到所需行的方式。常见的值包括:
类型 说明 All 全表扫描,最坏的情况 index 和全表扫描一样。只是扫描表的时候按照索引次序进行而不是行。主要优点就是避免了排序, 但是开销仍然非常大。如在 Extra 列看到 Using index,说明正在使用覆盖索引,只扫描索引的数据,它比按索引次序全表扫描的开销要小很多。 range 使用索引范围匹配多行数据,一个有限制的索引扫描。key 列显示使用了哪个索引。当使用 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE 或 IN() 运算符中的任何一个,将键列与常量进行比较时,会使用 range 。 ref 使用非唯一索引来匹配数据,返回所有匹配某个单个值的行。。此类索引访问只有当使用非唯一性索引或唯一性索引非唯一性前缀时才会发生。这个类型跟 eq_ref 不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是 UNIQUE 和PRIMARY KEY。ref 可以用于使用 = 或 <=> 操作符的带索引的列。 eq_ref 使用等值连接匹配一行数据,最多只返回一条符合条件的记录。当 join 连接时使用索引的所有部分并且索引是 PRIMARY KEY 或 UNIQUE NOT NULL 索引时,使用它。(通常用于 join 连接操作) const 该表最多有一个匹配行,该行在查询开始时读取。由于只有一行,因此该行中的列的值可以被优化器的其余部分视为常量。 const 表非常快,因为它们只被读取一次。将 PRIMARY KEY 或 UNIQUE 索引的所有部分与常量值进行比较时,将使用 const。(通常用于单表常量查询) system 该表只有一行。 Null 意味说 mysql 能在优化阶段分解查询语句,在执行阶段甚至用不到访问表或索引(高效) possible_keys: 显示可能被用于查询的索引。
key: 显示实际被用于查询的索引。
key_len: 显示被使用的索引的长度。在不损失精确性的情况下,长度越短越好 。
ref: 显示哪个列或常量与索引进行比较。
rows: 指示 MySQL 认为它必须检查才能执行查询的行数。
filtered: 表示在
WHERE子句中被过滤掉的行的百分比。Extra: 包含关于查询优化的其他信息。
类型 说明 Using index 表示查询使用了覆盖索引(Covering Index),即查询所需的数据可以直接从索引中获取,而不需要回表查询。 Using where 表示查询在检索数据时需要进一步的过滤操作,即需要在 MySQL 层面应用 WHERE子句中的条件。”Using where” 表示在查询执行过程中,优化器可能使用了索引来匹配部分查询条件,但是还需要进一步的操作来满足剩余的条件,这些条件可能不在索引中。常见情况例如回表查询,即查询需要返回的列不全部包含在使用的索引中,因此查询还需要回表查询来获取缺失的数据列。Using temporary 表示查询需要创建临时表来处理某些操作,如排序或分组。 Using filesort 表示查询需要进行文件排序操作,即 MySQL 需要将数据写入临时文件并对其进行排序,通常与 ORDER BY子句相关。可以通过选择合适的索引来改进性能,用索引来为查询结果排序。Distinct 表示查询需要对结果进行去重操作。 Not exists 表示查询使用了 NOT EXISTS子查询。Dependent subquery 表示查询使用了相关子查询(dependent subquery),即子查询依赖于外部查询。 Cached 表示查询结果来自缓存。 Using index condition 表示查询的一部分或全部查询条件可以在索引中进行求值,而不需要通过回表查询实际的行数据。这可以降低数据访问的开销,从而提高查询性能。
参考
MySQL EXPLAIN 官方文档:https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
MySQL SHOW PROFILE 官方文档:https://dev.mysql.com/doc/refman/5.7/en/general-thread-states.html
一次mysql order by desc 慢的排查:https://juejin.cn/post/6844903874839445517
https://z.itpub.net/article/detail/D14C1032130798C5D2E0B00C10905150